

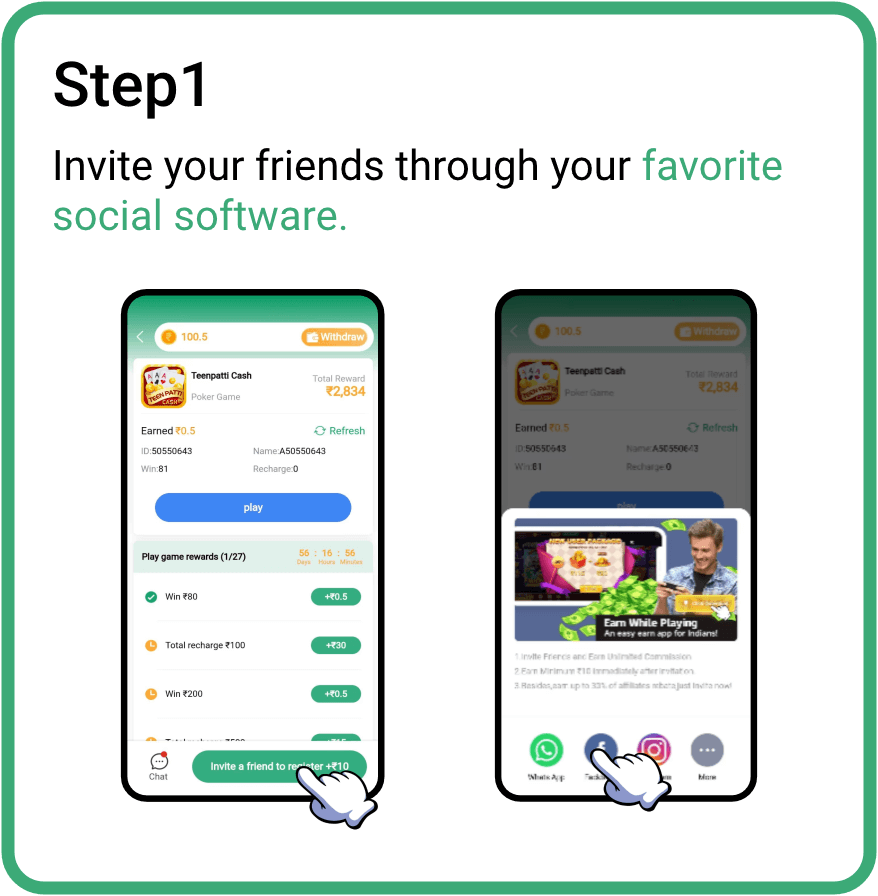
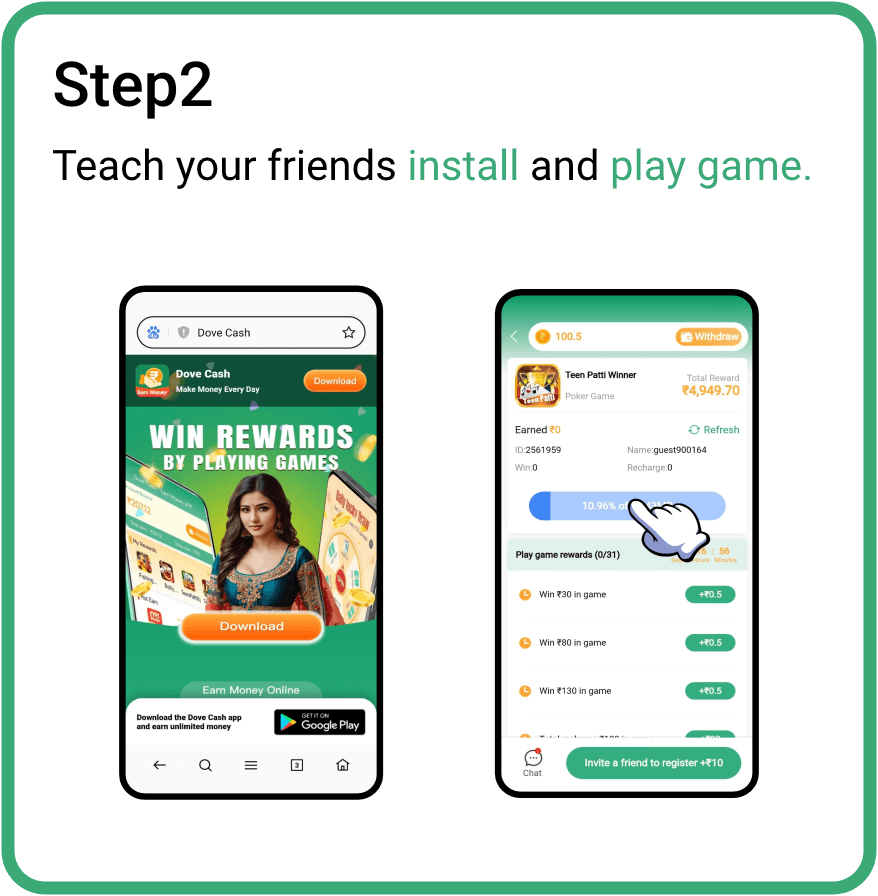
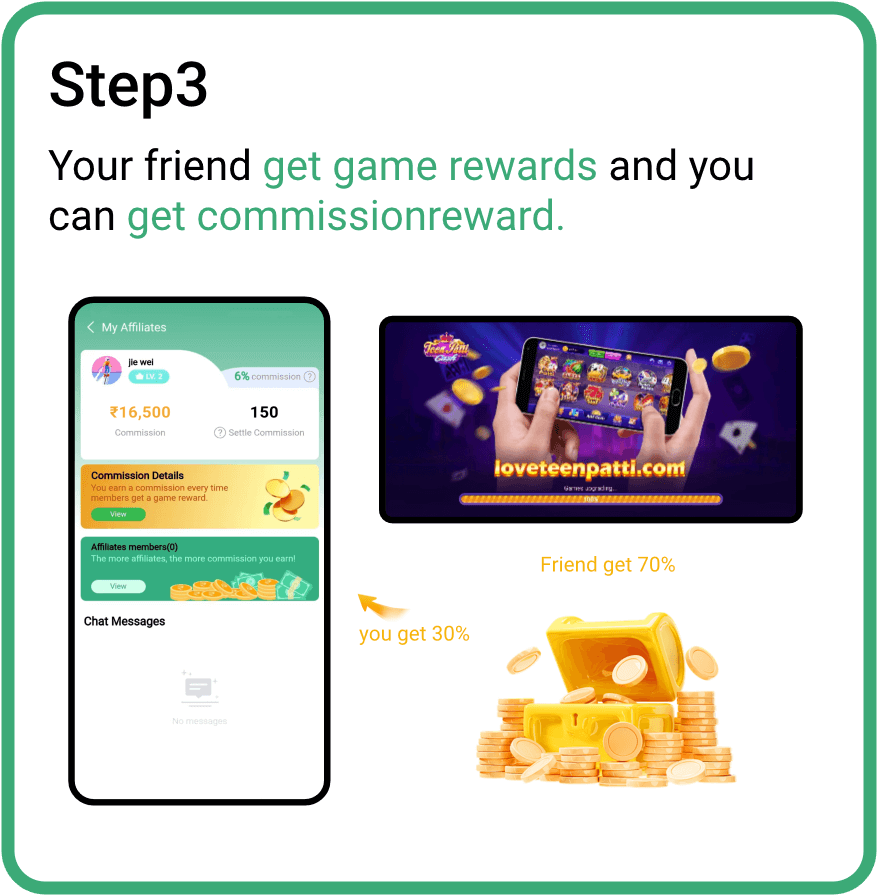
How to get affiliate commission ?
Invite friends to earn money together,and you will get more
commission rewards when your friends earn money.
commission rewards when your friends earn money.


If you meant this as a metadata or filename breakdown for archival/organizational purposes, I can help with:
The string you've provided, JUQ-450-EN-JAVHD-TODAY-04222024-JAVHD-TODAY01-5 , seems to follow a structured format. Let's break it down:
input_str = "JUQ-450-EN-JAVHD-TODAY-04222024-JAVHD-TODAY01-5" parsed_data = parse_string(input_str) JUQ-450-EN-JAVHD-TODAY-04222024-JAVHD-TODAY01-5...
: This likely represents the language of the content, in this case, English.
# Example usage input_str = "JUQ-450-EN-JAVHD-TODAY-04222024-JAVHD-TODAY01-5" print(parse_string(input_str)) If you meant this as a metadata or
def parse_string(input_str): # Split the string by dashes parts = input_str.split('-')
Given these observations, it seems that this string is used to identify and possibly organize or search for specific adult video content on a platform or database, likely one that specializes in Japanese adult videos. The detailed breakdown could suggest a system for cataloging and accessing content based on its language, type, quality, and release date. The detailed breakdown could suggest a system for
In conclusion, while the specific content associated with "JUQ-450-EN-JAVHD-TODAY-04222024-JAVHD-TODAY01-5" may not be detailed here, the context of JAVHD and similar identifiers highlights the broader trends in content consumption and production. As we move forward, the focus on quality, accessibility, and user experience will continue to shape the industry.